
Release notes for the Genode OS Framework 19.05
The Genode release 19.05 is primarily focused on platform support. It adds compatibility with the 64-bit ARM architecture (AARCH64), comes with improvements of the various kernels targeted by the framework, and extends the list of supported hardware. The increased diversity of base platforms calls for unifications to keep the hardware and kernel landscape manageable.
On that account, Genode uses one reference tool chain across all kernels and CPU architectures. The current release upgrades this tool chain to GCC 8.3 with C++17 enabled by default (Section Tool chain based on GCC 8.3.0 and binutils 2.32).
To increase the velocity of Genode system scenarios across different boards of a given CPU architecture, the release introduces the notion of board and kernel-agnostic build directories presented in Section Unified build directories for ARM. Once built for one particular CPU architecture, the same binaries can be deployed at any supported board or kernel without recompilation. This vastly accelerates the workflow when targeting multiple boards and emulators at once.
As another major unification effort, the current release introduces a new kernel-agnostic virtualization interface. Up until now, virtualization used to be inherently tied to a specific kernel. Thanks to the new interface, however, one virtual machine monitor implementation can be combined with kernels as different as NOVA, seL4, or Fiasco.OC. No recompilation needed. As outlined in Section Kernel-agnostic virtual-machine monitors, Genode has now become able to run the Seoul VMM on all those kernels, while VirtualBox is planned to follow.
On our road map, we originally planned several user-facing features related to Sculpt OS. However, in the light of the major platform efforts, we decided to defer those topics instead of rushing them. That said, the release is not without new features. For example, our port of OpenJDK has become able to host the Spring framework and the Tomcat web server, there are welcome improvements of the package-management tooling, and we added new options for user-level networking.
Finally, version 19.05 is accompanied with the annual revision of the Genode Foundations book (Section New revision of the Genode Foundations book), which is now available as an online version in addition to the regular PDF document.
Kernel-agnostic virtual-machine monitors
Since the introduction of Genode's Application Binary Interface in the 17.02 release, Genode components can be assembled once for a given hardware platform and executed without further adjustments on all the supported kernels. However, at that time, the supported virtual machine monitors - a port of VirtualBox 4 & 5, Seoul, and our custom VMM - remained kernel specific.
Of course, last remaining bastions tempt to be taken! So last year, we started the venture to unify our virtualization interface across different kernels. Starting point was the already existing Genode VM interface of our custom VMM on ARM. We took it and extended the interface with caution to the x86 world. Having an eye on the requirements of our already supported VMMs on NOVA(x86), namely VirtualBox and Seoul, the VM interface got extended with missing features like multiple vCPU support and specific VM handlers per vCPU.
In parallel, we started to investigate the other x86 microkernels with regard to hardware-assisted virtualization features, namely seL4 and Fiasco.OC. Over several weeks, we iteratively extended the interface. On the one hand we familiarized ourself with the kernel interfaces of seL4 & Fiasco.OC while on the other hand considered known requirements of the NOVA microhypervisor. Additionally, we kept our custom VMM for ARM still compatible with the new VM interface.
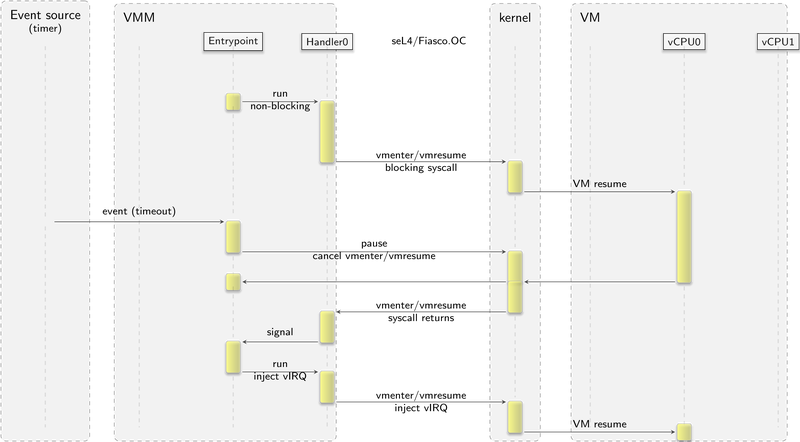
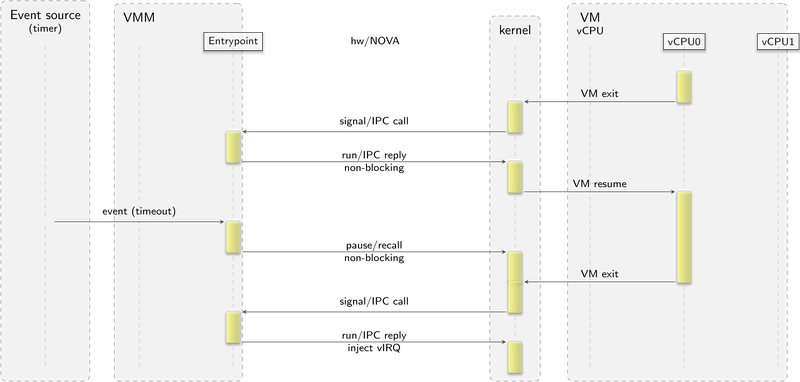
During this time, it became apparent that the control flow on a VM resume/pause and a VM event(exit) are different between seL4/Fiasco.OC and NOVA/base-hw. For seL4 and Fiasco.OC, a VM is resumed by making a blocking syscall on the kernel. On a VM event, the blocking syscall would return. Logically, on both kernels the VMM calls into the VM. On base-hw and NOVA, it is the other way around. Whenever a VM causes a VM event, the kernels set up either an asynchronous notification (base-hw) or a synchronous IPC call (NOVA) to the VMM. In both cases the VMM executes a prior registered VM event handler as response. Upon return of the VM event handler, the kernel resumes the VM. Logically, on NOVA and base-hw the VM calls into the VMM. The following two figures contrast the different flows of control between a user-level virtual machine monitor and the respective kernels.
|
|
Control flow of handling virtualization events on Fiasco.OC and seL4
|
|
|
Control flow of handling virtualization events on NOVA and the base-hw kernel
|
Hiding this differences behind a common VM interface was the challenge we were faced, accepted, and won. Finally, at one point in December we had all 3 x86 kernels running with a test VMM - without re-compilation. The toy VMM (vmm_x86.run) runs multiple vCPUs on multiple physical CPUs and tests several VM events/exits.
After this major breakthrough, we spent the days left before Christmas to adjust the Seoul VMM to the new VM interface, freeing it from the ties to the NOVA kernel. The choice to start with Seoul stems from the fact that it is - compared to VirtualBox - much smaller and therefore easier to debug if things go wrong in the beginning. After one week, the Seoul VMM became in principle kernel independent and worked again on NOVA. After some more days, it started to hobble on seL4 and Fiasco.OC as well.
With the New Year, VirtualBox was the next target where all NOVA kernel specific calls were replaced with the new Genode VM interface. Mid of January, the work showed first results by having a prototype running simple VMs on NOVA again. At this point, it became apparent that this venture is not anymore an adventure. All the findings and technical details so far got condensed to a presentation given and recorded at the FOSDEM 2019 in Brussels in February in the Microkernel and Component based OS developer room.
At this point, we started transforming our prototype for the 4 kernels into a clean solution to be featured in Genode 19.05. Eventually, the kernel-agnostic Seoul VMM runnable on seL4, Fiasco.OC, and NOVA entered Genode master. In the Genodians article Seoul VMM and the new VM interface, we conserved the current state and a few performance measurements.
Shortly before this release, the kernel-agnostic VirtualBox VMM version on Genode/NOVA got ready. The kernel-agnostic version is in principle capable to run Linux VMs and Windows 7/10 VMs on Genode/NOVA. Currently, this version must still be considered as experimental and does not run on seL4 or Fiasco.OC.
Because of the experimental nature of the kernel-agnostic VirtualBox VMM version, we decided to keep the kernel-specific version for NOVA for the moment. This gives us time to test and improve the kernel-agnostic version. It also allows us to compare both versions to each other. If time and interest permits, we will consider bringing the virtualization support on Genode/seL4 and Genode/Fiasco.OC on par with Genode/NOVA.
When building VirtualBox with Genode 19.05, you will find both the virtualbox5-nova and the new virtualbox5 binaries in the build directory. The former relies on NOVA's kernel interface whereas the latter uses Genode's kernel-agnostic VM interface. Nightly tested run scenarios with the new VM interface are named vbox5_vm*.run and can be found in the repos/ports/run directory.
Broadened CPU architecture support and updated tool chain
With the major update of Genode's tool chain and library infrastructure in tandem, the framework gains a consistent architecture support across x86-32, x86-64, ARM-32, RISC-V, and the newly added AARCH64. This includes the tool chain (Section Tool chain based on GCC 8.3.0 and binutils 2.32), the base framework, the dynamic linker, and the C runtime (Section Updated dynamic linker and C runtime).
Together with this update, we took the chance to wrap up our long-time move away from board-specific build directories to one generic build directory shared by multiple kernels and boards for a given CPU architecture (Section Unified build directories for ARM).
Tool chain based on GCC 8.3.0 and binutils 2.32
Genode uses a tailored tool chain based on GCC and binutils that is used across all supported kernels and architectures. Since the previous tool-chain update in version 17.05, we relied on GCC 6.3. After two years, it was time for an update, motivated by three major reasons. First, the C++17 standard is common-place now. We Genode developers anticipate the improvements that come with it. Second, RISC-V and AARCH64 are now supported by mainline GCC. Up till now, we had to maintain a custom patch set for Genode's RISC-V support. AARCH64 was not supported yet. Third, our increasing engagement with SPARK depends on recent improvements of the Ada compiler that is part of GCC.
With Genode 19.05, the tool chain is now based on binutils version 2.32, GCC version 8.3.0, GDB version 8.2.1, gcov version 8.3.0, standard C++ library version 8.3.0.
The tool chain supports x86 (32 and 64 bit), ARM, AARCH64, and RISC-V.
For C++ code, the C++17 standard is enabled by default.
The update of the tool chain provided a perfect opportunity to replace the former use of gnatmake with a much more natural integration of Ada in Genode's build system, using a custom ali2dep dependency-extraction tool developed by Componolit.
In contrast to the previous versions, we switched to a versioned installation directory for the new tool chain. By default, it is now installed to /usr/local/genode/tool/19.05/. This eases the use of different tool-chain versions for different development branches.
- Tool-chain installation
Caveats
The tool-chain update required a number of adaptations throughout the source tree, and may affect Genode users too:
-
The silent fall-though within switch statements must now be replaced by an explicit annotation of the form
[[fallthrough]]
-
The register keyword is no longer valid with C++17. Hence, it must be removed from the code.
-
Types marked as Noncopyable can no longer have an implicit default constructor. A default constructor must be provided manually.
Updated dynamic linker and C runtime
The tool-chain update is accompanied with a major update of the dynamic linker and the C runtime to cover both the AARCH64 and RISC-V architectures in addition to the traditional x86 and ARM architectures.
FreeBSD 12 supports AARCH64 and RISC-V. Hence, by updating our C runtime to this version, Genode's libc support extends to those architectures now.
Until now, Genode's dynamic linker supported only the eager binding of symbols at loading time on the RISC-V architecture. With the current version, we lifted this limitation in favor of lazy binding as used on all other CPU architectures.
Unified build directories for ARM
In version 17.02, we introduced unified build directories for x86, which allow us to build and run Genode scenarios on various kernels while using only one build directory. This concept leverages Genode's cross-kernel binary compatibility to make the switch from one kernel to another - like developing on base-linux and deploying on base-nova - a seamless experience.
On ARM, this concept was held back by a third dimension. The system-integration step does not only depend on the CPU architecture and the kernel but also on the used board. Our traditional approach was the use of one build directory per board. Granted, within such a build directory, one could easily switch between different kernels like Fiasco.OC and seL4. But on ARM, we find an extreme proliferation of different board configurations, which share the same CPU architecture but demand different integration steps. This ensues large redundancies among different build directories. Switching from one board to another - even when most binaries happen to be exactly the same - requires an additional rebuilding effort.
With version 19.05, we took the chance to generalize the unified build directory concept to support multiple different boards per build directory, greatly reducing the friction when switching kernels and boards for a given CPU architecture (like ARMv7a). This change has the following implications:
-
Drivers no longer depend on the SPEC values as configured for a build directory.
-
All binaries are now named unambiguously. For example, the USB drivers for the Panda (OMAP) and Arndale (Exynos) boards were formerly called usb_drv but were different programs. They just never happened to appear in the same build directory. In the new version, they are named panda_usb_drv and arndale_usb_drv respectively and can thereby peacefully co-exist within the same armv7a build directory.
Note that this binary renaming will likely affect existing run scripts.
-
Include paths no longer hide the board details, which makes the included code much more easy to follow.
-
Run scripts need to pick the right binary, depending on the used board. Since the board is no longer tied to a build directory, the selection of the used board has become a build-time variable BOARD following the successful pattern of how we specify the targeted KERNEL.
To avoid the pollution of run scripts with difficult conditions, we wrap the drivers needed for a particular board and use case into so-called drivers packages. Such a package can be instantiated within a generic scenario using a nested init instance. The details about the drivers and how they access the hardware remain nicely hidden inside this building block.
Currently, there exist drivers packages for two distinct use cases:
- drivers_interactive pkgs
-
contain all drivers needed for simple interactive scenarios, including graphical output and user input.
- drivers_nic pkgs
-
contain the drivers needed for communication over the network.
Whenever a run script fits one of these use cases, it can rely on the corresponding ready-to-use drivers packages via:
import_from_depot [depot_user]/src/[base_src] \
[depot_user]/pkg/[drivers_nic_pkg] \
...
With the drivers package incorporated, the drivers subsystem can be instantiated as follows (note the absence of any board or kernel-specific details):
<start name="drivers" caps="1000">
<resource name="RAM" quantum="32M" constrain_phys="yes"/>
<binary name="init"/>
<route>
<service name="ROM" label="config">
<parent label="drivers.config"/> </service>
<service name="Timer"> <child name="timer"/> </service>
<any-service> <parent/> </any-service>
</route>
<provides> <service name="Nic"/> </provides>
</start>
Using the BOARD build variable
The new BOARD variable selects the board to use. It can be specified either as a make command-line argument (or environment variable), or defined in the build-directory configuration (etc/build.conf). The following boards are available:
- arm_v6
-
rpi
- arm_v7a
-
arndale, imx53_qsb, imx53_qsb_tz, imx6q_sabrelite, imx7d_sabre, nit6_solox, odroid_x2, odroid_xu, panda, pbxa9, usb_armory, wand_quad, zynq_qemu
- arm_v8a
-
rpi3
- x86_64
-
pc, linux, muen
- x86_32
-
pc, linux
- riscv
-
spike
Please note, when running Genode on Linux or the Muen separation kernel - although it is run on common x86 PC hardware - we treat both runtime environments as separate "boards" because their device driver environments are fundamentally different.
New revision of the Genode Foundations book
The "Genode Foundations" book received its annual update, which is actually rather a refinement than a revision. The noteworthy additions and changes are:

-
Component health monitoring
-
Static code analysis
-
Documentation of –depot-user and –depot-auto-update
-
Minor adjustments in the under-the-hood chapter
-
Changes of the build system
-
Updated tool requirements
-
Updated API reference
To examine the changes in detail, please refer to the book's revision history.
New online version of the book
We are happy to announce that the Genode Foundations book is now available as an online version in addition to the regular PDF version.
- Browse the Genode Foundations book online
-
https://genode.org/documentation/genode-foundations/19.05/index.html
Thanks a lot to Edgard Schmidt for creating the tooling for the HTML version of the book!
Base framework and OS-level infrastructure
Modernized block-storage interfaces
With the current release, we revisited Genode's interfaces for accessing block devices to ease the implementation of asynchronous I/O, to accommodate zero-copy block drivers, and to support trim and sync operations.
Revised RPC interface
The Block::Session RPC interface remained untouched for a long time. We have now rectified long-standing deficiencies.
First, sync requests used to be handled as synchronous RPCs. This is bad for components like part_block that multiplex one block device for multiple clients. One long-taking sync request of one client could stall the I/O for all other clients. The new version handles sync requests as asynchronous block-request packets instead.
Second, the new version allows a server to dictate the alignment of block-request payload. This way, a driver becomes able to use the payload buffer shared between client and server directly for DMA transfers while respecting the device's buffer-alignment constraints.
Third, we added support for trim as an asynchronous block operation. However, as of now, this operation is ignored by all servers.
Fourth, each block operation can now be accompanied with a client-defined request tag independent from the other parameters of the operation. The tag allows a block-session client to uniquely correlate acknowledgments with outstanding requests. Until now, this was possible for read and write operations by taking the value of the request's packet-stream offset. However, sync and trim requests do not carry any packet-stream payload and thereby lack meaningful and unique offset values. By introducing the notion of a tag, we can support multiple outstanding requests of any type and don't need to overload the meaning of the offset value.
New client-side API
We have now equipped the Block::Connection with a framework API for the implementation of robust block-session clients that perform block I/O in an asynchronous fashion.
An application-defined JOB type, inherited from Connection::Job, encapsulates the application's context information associated with a block operation.
The life cycle of the jobs is implemented by the Connection and driven by the application's invocation of Connection::update_jobs. The update_jobs mechanism takes three hook functions as arguments, which implement the applications-defined policy for producing and consuming data, and for the completion of jobs.
We plan to gradually move the existing block clients to the new API to benefit from the latency-hiding effects of asynchronous I/O. The first updated client is the block_tester component located at os/src/app/block_tester/, which received a number of new features like the choice of the batch size. Please refer to the accompanied README for a detailed description of the block-tester.
Unified types for time values
Two years ago, we introduced the so-called timeout framework to provide a general solution for requirements unmet by the bare timer-session interface - most notably timer-session multiplexing amongst multiple timeouts, and microseconds accuracy. Up to this day, the timeout framework has proved itself many times in both real-life appliances and artificial tests and has become the standard front end for timing in Genode applications.
With this release, we solved one of the few remaining limitations with the framework by enabling timeouts of up to 2^64 microseconds (> 500000 years) across all supported architectures. In order to achieve this, we replaced the former machine-word-wide types used for plain time values by unsigned 64-bit integers. We did this not only inside the timeout framework but also to almost all code in the basic Genode repositories that uses the framework.
By doing so, we also paved the way for a second step, in which we are planning to replace plain time values as far as possible with the abstract Duration type. With this type in place, the user wouldn't have to worry anymore about any plain-integer implications when calculating with time values.
Support for chained EBR partitions
Having an active community around Sculpt leads to bugfixes in unexpected places. By now we prefer to use a GPT rather than an MBR based partition table and although we test part_block, the component that parses the tables, on regular basis, the handling of chained EBR's was flawed. Community member Valery Sedletski who relies on such a setup encountered this flaw and provided a bug report, which enabled us to quickly reproduce and fix the problem.
IP forwarding with port redirection
The NIC router can now be used to redirect to individual destination ports on port-forwarding. To express the redirection, the new to_port attribute can be added to <tcp-forward> and <udp-forward> rules in the NIC router configuration. If the new attribute isn't added, the rules behave as usual and forward with an unaltered destination port.
Libraries, languages, and applications
Ada/SPARK runtime and SPARK-based cryptography
The SPARK runtime has been updated to GCC 8.3. SPARK components do not require Genode::Env or a terminal session anymore. Debug messages can still be printed using GNAT.IO, which uses Genode::log and Genode::error internally now.
Threading support, which was never fully implemented, has been removed to further simplify the runtime. This simplification allowed us to prove absence of runtime errors for the secondary stack allocator and other parts of the runtime.
Libsparkcrypto is a library of common cryptographic algorithms implemented in SPARK. It is free-standing and has a very small footprint. The port of libsparkcrypto for Genode has been added to the libports repository. Thanks to Alexander Senier and Johannes Kliemann of Componolit for maintaining the Ada/SPARK runtime and libsparkcrypto.
To accommodate the use case of block encryption, we added the small wrapper library aes_cbc_4k around libsparkcrypto that provides a simple C++ interface for the en/decryption of 4 KiB data blocks. It uses AES-CBC while incorporating the block number and the private key as salt values.
Improved resilience of the sequence tool
We have a simple component that starts other components sequentially. It will exit whenever one of those components has exited with an error. However, this component is used by our Genodians appliance where it controls the content-update mechanism. Since updating involves fetching content via HTTP/S depending on external events, e.g., the remote site is not reachable, the sequence tool might exit. In a long running appliance, this is obviously not a useful action where no one is in place to restart the sequence tool. Rather than increasing the overall complexity of the appliance by introducing such a management component, we added a keep-going feature to the sequence tool that will instruct it to carry on even if one of the started components has failed.
Please look at repos/os/src/app/sequence/README for instructions on how to use the feature.
NIC-bus server for private LANs
The nic_bus server was added to the world repository as an alternative to the nic_router and nic_bridge components. The name may be a slight misnomer, but this component acts neither as a hub, switch, or router. The nic_bus implements unicast and multicast Ethernet packet switching between sessions, but drops any unicast packet not destined for a session attached to the bus. This is in opposition to the behavior of a typical Ethernet switch and is intending to create simple, software-defined local-area-networks for native components as well as virtual machines. In practice the component has been used for attaching VMs to the Yggdrasil overlay network via a bus-local IPv6 prefix.
Distributed Genode
In 16.08, we initially released the remote_rom components that act as communication proxies. A communication proxy transparently relays a particular service to another Genode system. As the name suggests, the remote_rom relays ROM sessions.
Originally implemented as a proof of concept using bare IP packets, broadcast MACs and static configuration of IP addresses, we added several improvements to allow a more general use. First, we adopted the size-guard idea for packet construction and processing from the NIC router. Furthermore, we adopted the single-threaded implementation style that was already established in other NIC components. Thanks to Edgard Schmidt for this contribution. Second, we implemented ARP requests to eliminate broadcasting. Third, we moved from bare IP packets to UDP/IP and implemented a go-back-N ARQ strategy in order to reliably transmit larger ROM dataspaces.
As the remote_rom proved valuable for distributing functionality across multiple Genode devices, we also applied this concept to the LOG session in order to transmit LOG output from a headless Genode device to a Sculpt system for instance. The udp_log component provides a LOG service and sends the LOG messages as UDP packets to another machine. The log_udp reverses this process by receiving these UDP packets and forwarding the messages to a LOG service. An example can be found in the world repository at run/udp_log.run and run/log_udp.run.
Seoul and VirtualBox virtual machine monitors
Besides the conversion of the Genode back end of Seoul to the new VM interface, we added mouse-wheel support to the PS/2 model and changed the VMM to request a single GUI/nitpicker session rather than distinct framebufer and input sessions.
Similar to the Seoul VMM, the VirtualBox VMM was adjusted to the new VM interface and now uses the GUI/nitpicker session. The original kernel-specific VirtualBox version tied to the NOVA kernel is still available. Both versions can be used simultaneously.
Use of Nim decoupled from Genode build system
With this release, all integration with Nim tooling has been removed from the Genode build system as a result of maturing support for additional languages via Genode SDKs. Building Nim components independently of the Genode source tree has the benefit of smaller upstream checkouts and faster build times, and has yielded components such as the 9P server used in some Sculpt developer workflows. An example of an independent build system for Nim components is documented on the Genodians blog.
OpenJDK improvements
Within the 19.05 release cycle, we further improved Genode's OpenJDK support by enabling additional networking infrastructure required by the Spring Framework. The improvements especially concern support for SSL connections, which enabled us to successfully execute an embedded Tomcat server natively on Genode x86 and ARMv7 platforms using the same JAR archive. This line of work continues our Java for embedded systems effort as described in our Boot2Java article.
Having these features in place, our Java efforts will continue in the direction of Java Swing and the support of input devices in the future, with the ultimate goal of seamless Java application integration into Sculpt OS.
Device drivers
Improved Zynq board support
The initial support of the Xilinx Zynq-7000 SoC was added to our custom kernel in 15.11. Since then, the support of this hardware has been incrementally extended. The definitions of memory maps, frequencies, and RAM sizes for different Zynq-based boards are found in the world repository.
One of the major additions in this release is the initialization of the L2 cache. In this context, we also added a simple cache benchmark at repos/os/run/cache.run that measures the access times for memory regions of different size and thereby reveals the number of cache levels and their sizes.
With the latest improvements of the network driver in 18.11, a zero-copy approach was introduced as an effort to eliminate bottlenecks in the driver's performance. However, this modification also introduced a kernel dependency of the driver in order to flush packet-buffer memory from the cache before handing it over to the DMA-controller. With this release, we moved back to using uncached dataspaces in order to eliminate the cache flushes and the kernel dependency. Interestingly, we could not recognize a significant impact on the driver's performance, which confirms the presumption that flushing the cache nullifies the gain from using cached dataspaces.
In order to enable the continuous operation of the network driver, we extended the driver-internal error handling that is necessary to recover the network driver in certain situations.
Thanks to Johannes Schlatow for contributing and maintaining Genode's Zynq support!
Updated Intel network drivers
As a result of recurring issues with modern Intel i219 laptop NICs, we updated the driver sources for Intel chipsets to the latest upstream iPXE version. This update also enables all NIC variants, which were missing from our manually maintained PCI ID whitelist before.
New drivers-nic and drivers-interactive depot packages
As already described in section Unified build directories for ARM, drivers_nic packages nicely hide the driver configuration internals needed for a specific board to communicate over the network. Until now there was only one package available for x86 based PCs. Now, additional drivers_nic packages are available for:
- boards
-
imx53_qsb imx6q_sabrelite linux muen pbxa9 rpi zynq
Beside the formerly available drivers_interactive packages for linux, pbxa9 and pc, there are now additional ones for the following:
- boards
-
imx53_qsb rpi muen
Platforms
For most kernel environments, the core component provides a ROM module named platform_info, which comprises information provided by either the kernel or the bootloader. The information entails e.g., the TSC clock frequency and framebuffer dimensions. Most of the information is of interest for special device driver components only.
Over the time, there was an increasing need to incorporate the information about which kernel Genode runs on top of. Thereby, special test components, like depot_autopilot could use the information to, e.g., skip certain tests on kernels known to not support them. Moreover, there are rare corner-cases where kernels behave differently, for instance, interrupts are enumerated differently on certain ARM platforms. Rather than maintaining multiple driver binaries with different names depending on specific kernels, the platform_info ROM module can now be used to differentiate between kernels when necessary.
Execution on bare hardware (base-hw)
This release comes with fundamental optimizations and corrections for executing Genode on bare hardware when using the core component as the actual kernel.
In the past, we could observe some serious peculiarities regarding the timing behavior on the hw kernel. After a careful review, we identified the obstacles that led to time drifts on several platforms and to quite different runtime execution.
First and foremost, we limited the CPU-load wasted by the kernel, which unnecessarily made new scheduling decisions quite often. When the hw kernel was started as an experiment, there was less focus on performance, but more on simplicity. Instead of caring about state changes that make a scheduling decision necessary, the scheduler was asked for the next execution context unconditionally, whenever the kernel was entered. Now, the scheduler gets invoked only whenever an execution context gets blocked, or unblocked, or if the kernel's timer fires due to a timeout. This dramatically influences the CPU-load caused by the hw kernel in a positive way.
The timing accuracy got increased by reworking most hardware timer drivers used in the kernel to let the timer never stop counting. Moreover, we limit the scope in between reading the clock and adjusting the next timeout to a minimum. The whole internal time representation got widened to 64-bit.
In some rare use cases, we could observe components that do I/O polling, and thereby actively ask for pending signals, to starve. The reason was a gap in the hw kernel's syscall API. Beside the ability to wait for signals, the base-library offers the ability to check for pending signals without blocking in the case of no available signals. The equivalent call in the kernel was still missing, and is now present and integrated in the base-library of base-hw.
ARM architecture
With this release, we add the i.MX 7 Dual SABRE reference board to the rich hardware zoo Genode runs directly on top of. This includes the use of the virtualization extensions available on this platform.
Apart from the new board support, several optimizations were added specifically for the ARM architecture. Several unnecessary cache maintenance operations were eliminated, which resided in the code base since the time when the kernel used a separate address-space only. Moreover, the kernel-lock - used when several execution contexts on different CPU-cores try to enter the kernel - does not spin anymore. Instead, the CPU goes into a sleep-state to save energy. As a side-effect, multi-core scenarios become usable when executed in Qemu.
X86 architecture
Since the newly used compiler version makes aggressive use of FPU instructions including the core component, the kernel itself makes use of FPU registers and state. Therefore, lazy FPU switching becomes a no go for base-hw. Although, we incorporated eager FPU switching into the ARM-specific part of the hw kernel already, the x86 version was still missing it. Now, the FPU context of a thread gets saved and restored on every kernel entry and exit on x86 too.
Updated Muen separation kernel
The Muen port has been updated to the latest development version, which comes with many improvements under the hood. Most notably this version of Muen brings support for Linux SMP subjects, GNAT Community 2018 toolchain support as well as much improved build speed, which is most noticeable during autopilot runs.
Additionally, the debug server buffer size in the Genode system policy has been increased to avoid potential message loss in case of rapid successive logging.
Thanks to Adrian-Ken Rueegsegger of Codelabs for this welcome contribution!
NOVA microhypervisor
The kernel got updated due to the tool-chain update to GNU G++ 8.3.0. Additionally, several issues reported by Julian Stecklina regarding FPU and page-table synchronization got addressed. The kernel memory allocation at boot time got more flexible to address target machines with fragmented physical memory. Additionally, the vTLB implementation is no longer used on AMD machines whenever nested paging is available.
seL4 microkernel
With this release, we extend the variety of hardware to run Genode on top of the seL4 kernel with NXP's i.MX 7 Dual SABRE reference board. To do so, we had to update the seL4 tools used to craft a bootable ELF image to a state that is consistent with the currently supported seL4 kernel version 9.0.1.
As a side-effect of this development work, the General Purpose Timer (GPT) used in the i.MX series can now be used as a timer service component.
Fiasco.OC microkernel
As with base-hw and seL4, we add the i.MX 7 Dual SABRE reference board to the list of working hardware for Genode running on top of the Fiasco.OC microkernel. Moreover, with Fiasco.OC it is now possible to take the first steps using Genode on the ARM 64-bit architecture. Therefore, we add Raspberry Pi 3 as a candidate board to be used with Genode/Fiasco.OC. Currently, only basic tests without peripheral dependencies are supported.
Tooling and build system
Improved handling of missing ports
The depot tools tool/depot/create and tool/depot/extract now detect and report all missing third-party sources - called ports - for a given set of archives at once. Additionally, the user can tell the tools to download and prepare such missing ports automatically by setting the argument PREPARE_PORTS=1. Please be aware that doing so may cause downloads and file operations in your contrib/ directory without further interaction. These features make building archives with dependencies to many ports more enjoyable. If you merely need a list of ports that are missing for your archives, you can use the new tool tool/depot/missing_ports.
For more details you may read the article on genodians.org.
Automated depot management
When using the import_from_depot mechanism of the run tool, one frequently encounters a situation where the depot lacks a particular archive. Whenever the run tool detects such a situation, it prompts the user to manually curate the depot content via the tool/depot/create tool. The need for such manual steps negatively interferes with the development workflow. The right manual steps are sometimes not straight-forward to find, in particular after switching between Git branches.
To relieve the developer from this uncreative manual labor, we extended the run tool with the option --depot-auto-update for managing the depot automatically according to the needs of the executed run script. To enable this option, use the following line in the build configuration:
RUN_OPT += --depot-auto-update
If enabled, the run tool automatically invokes the right depot-management commands to populate the depot with the required archives, and to ensure the consistency of the depot content with the current version of the source tree. The feature comes at the price of a delay when executing the run script because the consistency check involves the extraction of all used source archives from the source tree. In regular run scripts, this delay is barely noticeable. Only when working with a run script of a large system, it may be better to leave the depot auto update disabled.
Please note that the use of the automated depot update may result in version updates of the corresponding depot recipes in the source tree (recipe hash files). It is a good practice to review and commit those hash files once the local changes in the source tree have reached a good shape.