
Release notes for the Genode OS Framework 17.02
After the revision of Genode's most fundamental protocols in the previous release it was time to move our attention upwards the software stack. The current release largely revisits the integration of the C runtime with the Genode component API as well as the virtual-file-system (VFS) infrastructure. The two biggest challenges were making Genode's VFS capable to perform I/O asynchronously, and to make the C runtime compatible with the state-machine-based execution model of modern Genode components. This line of work is described in detail in Sections Enhanced VFS infrastructure and New execution model of the C runtime. One particularly exciting result is the brand-new ability to plug the Linux TCP/IP stack as a VFS plugin into any libc-using component by the sole means of component configuration.
The second highlight of the current release is the introduction of Genode's application binary interface (ABI) along with kernel-independent build directories. This means that the binary executables of all Genode components have become kernel-agnostic by default. Entire system scenarios can now be moved from one kernel to another in just a few seconds. This does not only boost the development work flow but also paves the ground for the upcoming package management.
As the third major feature, Genode's init component received a far-reaching update that enables its use as a generic subsystem-composition engine that is able to apply changes to the hosted subsystem in a differential way. The improvements described in Section Dynamically reconfigurable init component greatly ease the realization of sophisticated system scenarios like multi-staged booting, interactive installers, or a desktop environment.
At the platform level, we are happy to announce the update of Genode's support for the Muen separation kernel version 0.8. The new version comes with much improved life-cycle management of Muen kernel subjects (Section Update of Muen to v0.8).
Functionality-wise, the most significant new feature is a generic user-input event filter described in Section OS-level infrastructure and device drivers. It allows the use of an arbitrary number of input devices, the application of key remappings, and dynamic switching between keyboard layouts.
Last but not least, on a non-technical level, the Genode OS Framework has updated its regular open-source license as announced earlier. After carefully reviewing the open-source license landscape, consulting the Genode developer community as well as the Free Software Foundation, Genode adopts the GNU Affero General Public License version 3 (AGPLv3) as its regular open-source license. To counter possible license-compatibility concerns with other popular open-source software licenses, Genode's AGPLv3 is accompanied with a special exception clause that expresses our consent with linking Genode with open-source software of different licenses. For the full license text including the linking-exception clause, please refer to https://genode.org/about/LICENSE.
Genode Application Binary Interface
One of Genode's most distinctive features is the ability to use the framework across a variety of OS kernels, which are as different as L4, Linux, NOVA, or seL4. Thanks to the framework's kernel-agnostic application programming interface (API), a component developed using one particular kernel can be used on any of the other kernels by merely recompiling the component. In version 16.08, we went a step further by attaining cross-kernel binary compatibility of Genode components and thereby - in principle - eliminated the need for a kernel-specific recompilation step. At the time, however, the cross-kernel binary compatibility had little practical value because the tooling and work flows made a hard distinction between different kernels, i.e., a build directory was tied to a particular kernel. With the current release, we finally leverage and cultivate cross-kernel binary compatibility to a degree that makes the choice of the kernel a minor configuration detail at system-integration time. Entire system scenarios can be moved from one kernel to another in just a few seconds. To make this possible, we had to take the steps described as follows.
Linking all components dynamically by default
By linking a component dynamically, the component's executable ELF binary solely contains application code but no code that directly interacts with the kernel. All kernel interactions happen through the dynamic linker, which is kernel-specific. It is still possible to build components that use special kernel features (like NOVA's virtualization mechanism) and directly interact with the underlying kernel. But those are very rare exceptions.
Besides separating the application code from the kernel-specific code, the dynamic linking has the additional advantage of significantly reducing the size of the ELF executables. Naturally, it implies the need to include the dynamic linker in all system scenarios (run scripts) now because even the lowest-level components (like init or the timer driver) are dynamically linked now.
Static linking is still supported. However, for linking such a target, one needs to define the particular kernel in the target's build description by specifying the kernel's corresponding base library. For example, instead of specifying LIBS += base, one needs to specify LIBS += base-nova. That said, in practice, this option is almost unused.
Formalizing the binary interface of the dynamic linker
By linking components dynamically, it is still a requirement to have a concrete instance of the dynamic linker to produce the component's ELF binary because the component depends on the dynamic linker as a shared library (i.e., the base libraries).
To loosen this dependency, we had to decouple the kernel-specific implementation of the dynamic linker from its kernel-agnostic binary interface. The name of the kernel-specific dynamic linker binary now corresponds to the kernel, e.g., ld-linux.lib.so or ld-nova.lib.so. Applications are no longer linked directly against a concrete instance of the dynamic linker but against a shallow stub called ld.abi.so. This stub contains nothing but the symbols provided by the dynamic linker. It thereby represents the Genode ABI.
At system-integration time, the kernel-specific run/boot_dir back ends integrate the matching kernel-specific variant of the dynamic linker as ld.lib.so into the boot image. The ld.abi.so is not used at runtime.
The dynamic linker's binary interface has the form of a symbol file located at base/lib/symbols/ld. It contains the joint ABIs of all supported architectures including x86_32, x86_64, ARM, and RISC-V. The fact that we can represent Genode's ABI in an architecture-independent way was quite surprising to us. There was only one noteworthy road block, which is the compiler-provided definition of __SIZE_TYPE__, which varies between 32-bit and 64-bit architectures. On the former architecture, it is an alias for unsigned int whereas on the latter, it stands for an unsigned long. This becomes a problem for C++ symbols where the function signature contains a size_t argument. For example, the hypothetical method void Connection::upgrade_ram(size_t) would result in the following mangled symbols as used by the linker:
x86_32: _ZN10Connection11upgrade_ramEj x86_64: _ZN10Connection11upgrade_ramEm
We worked around this immediate problem by eliminating the use of __SIZE_TYPE__ from Genode's API. Instead of using size_t, we now use a custom Genode::size_t type that always is an alias for unsigned long. That said, the problem will re-appear once we create ABIs for C++ libraries that use the regular size_t type on top of Genode. To ultimately solve this problem, our next tool-chain update will potentially unify the __SIZE_TYPE__ at the tool-chain level.
Generalization of the ABI mechanism
Realizing that the separation of a library's binary interface from a concrete library instance may be useful not only for Genode's dynamic linker but for arbitrary shared libraries, we enhanced Genode's build system with the general notion of "ABIs". An ABI for a library has the form of a symbol file located at lib/symbols/<library>. If present for a given library, any target that depends on the library is no longer being linked against the actual library itself but against the library's corresponding <library>.abi.so ABI stub library, which is created from the symbol file. The new utility tool/abi_symbols eases the creation of such an ABI symbol file for a given shared library. However, the extraction of an ABI from a library is not an automated process. ABIs must be maintained manually.
The build-system support for ABIs allows us to introduce intermediate ABIs at the granularity of shared libraries. This is especially useful for slow-moving ABIs such as the libc interface and clears the way for Genode systems with different layers of ABI stability. For example, even if Genode's ABI changes over time, all software that merely depends on the libc ABI (like most of the software ported to Genode) will still work with the updated Genode version.
Unified build directories
With the Genode ABI in place, we became able to use different kernels from within the same build directory. Of course, this change comes with a slight change of the tooling, in particular to the create_builddir tool, the build system, and the autopilot tool.
The tool/create_builddir tool accepts new platform options that are presented when starting the tool without arguments. The original kernel-specific platform arguments are still there but they are marked as "deprecated" and will be removed during the next release cycle. The new unified build directories are the way to go now. There is one option for each supported hardware platform, e.g., x86_64, or usb_armory. Note that the kernel is left unspecified.
After creating a new build directory, its etc/build.conf file refers to a KERNEL variable, which has the following effects:
-
It selects kernel-specific run-tool arguments KERNEL_RUN_OPT,
-
It selects kernel-specific Qemu arguments, e.g. QEMU_OPT(nova)
-
It adds the kernel-specific base-<kernel> directory to the list of source-code REPOSITORIES.
Like usual, to build a Genode component, e.g., init, one can invoke the build system via, e.g., make init. But in contrast to previous Genode versions where this command prompted the build system to implicitly compile Genode's base libraries, the command quickly builds the init component only. In fact, for compiling and linking the init component, only Genode's API (the header files) and ABI (the symbol file for the dynamic linker) are required.
At this point, the build directory is still void of any kernel-specific build artifacts. The decision for a particular kernel is not needed before integrating a system scenario, which naturally depends on a kernel. Hence, when executing a run script, one has to tell the run tool about the kernel to use, e.g., make run/demo KERNEL=nova. This step will eventually build many components, most of which are kernel-agnostic. When specifying another kernel on a subsequent run, those components are not rebuilt. Hence, switching from one kernel to another within the same build directory is just a matter of adjusting the KERNEL argument. This has the following immediate benefits:
-
When using multiple kernels, there is no need to have multiple build directories. After waiting an hour to build a Qt5-based scenario on NOVA, it is now possible to test-drive the same scenario on Linux in a few seconds because the same binaries will be reused.
-
If an executable has a bug, the bug will be there regardless of the kernel being used. To debug the problem, one can use the kernel with the most appropriate debugging instruments available.
-
The packaging of kernel-agnostic binary packages has become within close reach now.
-
The autopilot tool, which executes batches of run scripts across several platforms has gained a new -k argument that denotes the kernel to execute. It can be specified multiple times in order to execute all tests on multiple kernels. Since all tests use the same build directory, the tested components are executed on several kernels but are built only once.
Enhanced VFS infrastructure
The virtual file system (VFS) of Unix-based operating systems is probably one of the most characterizing features of Unix. The user-visible file system is exposed as a single hierarchic name space that comprises the contents of an arbitrary number of physical storage devices. The position (mount point) of each physical file system within the VFS can be anywhere. Thereby, technicalities like physical devices and partitions - where files are stored, or the file-system types - become completely transparent to applications. The VFS truly enables the metaphor of "everything is a file", which makes the user interface of Unix simple yet powerful.
In contrast, Genode evolved from a different perspective where any kind of global name space is suspected as a security risk. Security-sensitive and untrusted ( potentially malicious) applications should never share the same global view of the system. Instead, each application should only see the parts that it needs to see in order to fulfill its legitimate purpose. Hence, the idea to represent all system resources in one global namespace, as done by the VFS on Unix, contradicts Genode's underlying principle of least privilege. For this reason, Genode's architecture has no notion of files or a VFS.
That said, enjoying the power of Unix's user interface (e.g., shells, pipes) on a daily basis, it goes without saying that we desired to have an equally flexible user interface available for Genode. This is why the Noux runtime environment was born, which is a Genode subsystem that implements a Unix-like interface on top of Genode and is thereby able to host command-line based GNU software like coreutils, bash, binutils, gcc, or vim. For enabling the Noux runtime, we implemented a simple VFS that is assembled from Genode sessions and presented as a file system to the applications executed on top of Noux. In contrast to traditional Unix-like OSes that use one VFS in the OS kernel, our approach envisioned many Noux instances, each having a tailored VFS. This relieved our VFS implementation from the burden of implementing access control between processes running within the same Noux instance because access would be controlled at the granularity of Noux instances instead.
Thanks to Noux' built-in VFS, it became very easy to bridge the gap between the Genode world (of services and sessions) and POSIX applications running within Noux. As this became apparent, we desired the same flexibility to be available to regular Genode components. Hence, we extracted the VFS implementation from Noux in the form of a VFS library, and created a libc back end that uses this VFS library. Consequently, each Genode component that uses the libc has its private virtual file system that can be assembled from Genode sessions. This way, we combine the best of both worlds - Unix and Genode. Like the VFS on Unix, applications are not bothered with the technical details of where and how files are stored, or what the files really represent (devices, named pipes, actual files). Unlike Unix, however, each component has its own VFS that is tailored by the component's parent.
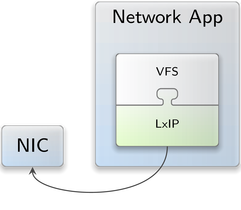
With the added support for asynchronous I/O in the current release, the full potential of Genode's approach to virtual file systems becomes apparent: As file-system types are handled as plugins, each VFS-using component automatically becomes equipped with a powerful plugin interface. For example, thanks to the new VFS-rump-kernel plugin, a rump kernel can be mounted as a file-system provider into any VFS-using component simply by configuring the component's VFS. As another example, the VFS-lxip plugin allows mounting the Linux TCP/IP stack inside the component-local VFS such that a socket-API-using application can use this TCP/IP stack.
|
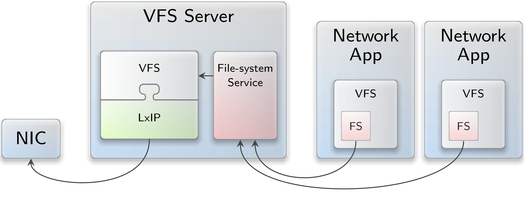
Whenever (parts of) one VFS need to be shared among multiple components, the VFS-server component comes in handy. It is a server that uses the VFS library internally and, in turn, provides the VFS content as a file-system service to other components. Such components can access the VFS server's file system from their respective VFSes by mounting a file-system session. This way, the VFS server combined with the VFS-lxip plugin suddenly becomes a socket-API multiplexer.
The lines between a multi-server OS and unikernel OS have become really blurry now.
|
VFS support for asynchronous I/O and reconfiguration
I/O operations in the VFS used to be synchronous in the context of Noux. This means in particular that users of the VFS were blocked until the requested operation succeeded or returned an error. Such behavior becomes cumbersome in cases where synchronous operations should have a bounded execution time or are completely undesired. The most prominent example is the VFS server, which potentially serves multiple clients. Unbounded blocking of operations requested by one client renders operations of other clients impossible until their completion. An asynchronous I/O approach paves the way to handle multiple contexts with operations that may complete at a later point in time.
For the introduction of asynchronous I/O in the VFS, we had to adapt several parts of the implementation.
First, the plugin interface of the VFS was extended to support signal handlers that react to I/O activity in a specific back end. For example, the terminal VFS plugin now registers a signal handler at the terminal server. The signal handler is notified whenever new data is available. From the context of those signal handlers, plugins are able to inform upper layers about the I/O activity via an I/O response-handler callback.
The user of the VFS, in turn, may take advantage of the added read_ready(handle) method to probe if an open VFS handle is readable resp. a consecutive read operation would return available data. The terminal plugin, for example, maps this function to the avail RPC of the terminal session. Further, the read operation is split into two phases. First, queue_read indicates the caller's intent to execute a read operation. This method may return OK immediately accompanied by the read data but may also return QUEUED if the operation was not completed. The optional second phase to complete the queued operation is requested with the complete_read method, which probes for the completion of an operation and should be called as a response to I/O activity, i.e., in the I/O response-handler callback. Our example of the terminal plugin checks if data is available at the terminal via RPC and returns the bytes read or QUEUED in both phases.
The implementation of the file-system-session VFS plugin appears a bit more complicated due to the packet-stream-based interface. We will spare you the details here, except that we added a new packet type to the session interface in order to probe open file-system handles for READ_READY. The server in turn notifies clients about readable handles out-of-band by acknowledging corresponding READ_READY packets. These acknowledgments can then be processed in the signal handler and notify the user of the VFS via the I/O response callback. The most prominent case where READ_READY is used indirectly is the implementation of select within the libc.
The VFS library originates from Noux, which instantiates one single VFS for all its children upon startup. Equally, the libc only provided one statically configured tree of directories and files for components as well. In contrast, recent plugins would heavily benefit from reconfiguration at runtime, e.g., setting or changing properties of the network stack described below. For this reason, we revised the configuration of VFS plugins. In the past, the configuration was passed to the constructor of plugins on instantiation only. With this release, we added the apply_config method to the API to support passing an updated XML configuration node to the plugin. We also extended the implementation of the directory plugin to traverse its registered file systems during configuration update.
Rump-kernel-based file systems as VFS plugin
This release adds two new VFS plugins to Genode. The first is an adapter to the Rump-kernel-based file-system library, which is also used by the standalone rump_fs server component. Like the server, the plugin allows for mounting one single block session as a file system. The plugin can be instantiated for ext2, msdos, or ISO file system like follows.
<vfs> <rump fs="ext2fs"/> </vfs> or <vfs> <rump fs="msdos"/> </vfs> or <vfs> <rump fs="cd9660"/> </vfs>
As the plugin is built as a VFS-external shared library, it must be compiled explicitly as target lib/vfs/rump and integrated as vfs_rump.lib.so into the system. For the impatient, there is a ready-to-use run script, which can be tried out via make run/libc_vfs_ext2.
Linux TCP/IP stack as VFS plugin
The second VFS plugin represents a new approach to share a single TCP/IP stack instance between multiple components. Our approach is heavily inspired by the Plan 9 namespaces where network sockets are accessible via files and we, therefore, named it socket file-system. The predominant feature of this approach is that it does not require a new session interface but simply plugs networking into the VFS server.
The socket file system appears as a tree of directories and files, which can be integrated into components as follows.
<vfs> <dir name="socket"> <lxip dhcp="yes"/> </dir> </vfs>
In this case, the Linux TCP/IP stack is instantiated via the vfs_lxip.lib.so plugin and configured for automatic network configuration via DHCP. From the perspective of the component, a directory /socket appears with the following contents.
/socket/tcp/ /socket/tcp/new_socket /socket/udp/ /socket/udp/new_socket /socket/address /socket/netmask /socket/gateway /socket/nameserver
The last four files reflect the current network configuration as ASCII text of IP addresses. More interesting are the new_socket files in the tcp and udp directories as those enable the component to create network sockets by opening them and reading the name of the just created TCP or UDP socket. Again, the content of the file is just ASCII text to support easy scripting in the future. After creating a new TCP socket, the socket fs will create a new socket directory. The directory contains a handful of files, which provide an interface to operate on the socket. It looks like the following example.
/socket/tcp/new_socket /socket/tcp/1/ /socket/tcp/1/bind /socket/tcp/1/connect /socket/tcp/1/data /socket/tcp/1/local /socket/tcp/1/remote
The TCP socket 1 in its initial state is exactly like any BSD socket - neither bound to any port locally nor connected to any remote server. These operations can be requested by writing an IP address plus port into the bind and connect files, e.g., write 0.0.0.0:80 to bind or 88.198.56.169:443 to connect. The result of those operations is reflected by the local and remote files. The actual data transfer happens via read/write operations on the data file. A socket can easily be closed by deleting (unlinking) the actual socket directory. In the case of connection-less datagram-oriented UDP sockets, the source or target address of a datagram is stored in the local resp. remote file.
For libc-using components, all peculiarities of the socket file system are implemented in a way that maps the BSD socket API to VFS operations if configured. For the time being, it is still possible to use the existing lwip or lxip libc networking libc plugins but those will eventually be removed. To use the VFS-based socket API, the libc has to be pointed to the location where the socket file system is located in its VFS:
<libc socket="/socket"/>
As described in VFS support for asynchronous I/O and reconfiguration, the VFS lxip plugin supports reconfiguration at runtime. This can be used to change the manual address configuration or just renew the DHCP configuration.
New execution model of the C runtime
With this release, we revised the execution model of libc-based components from ground up. The motivation for this work was to enable the implementation of components, which use Genode signal handlers or provide an RPC interface but also contain application code that uses C libraries and expects POSIX features like select to work.
|
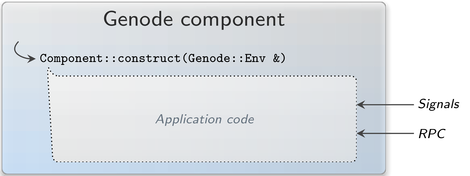
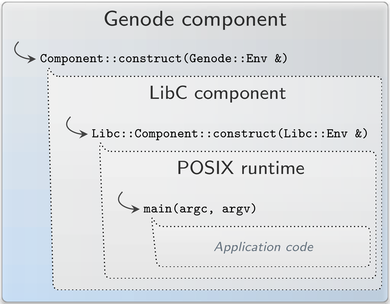
To understand the changes we did, let's first have a look at a regular Genode component. The life cycle of the component begins with the execution of the Component::construct function, which under the hood is also the very first RPC that is processed by the component. The originator of this RPC is the initial thread of the component while the component code is executed by the entrypoint. After construction, components return into the entrypoint and work in a reactive manner like a state machine. Events from the outside can occur in the form of incoming RPC requests or signals. The handling of those events affects the internal state but eventually the code just returns into the entrypoint and waits for further events.
|
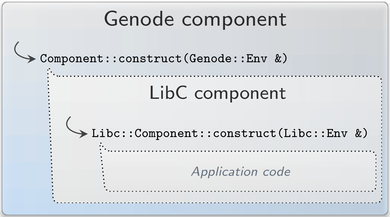
Looking from ten thousand feet, a libc-based component is not different from a regular Genode component and reacts on events from the surrounding system. The crucial difference lies in the semantics of the POSIX file operations, which may block on read or select. Therefore, the Component::construct function is not implemented in the component code but in the libc. On startup, this function prepares the C runtime, including the VFS, before executing the application (or libc-using component) code. The actual application is then entered via Libc::Component::construct on its own application context (stack and register set). Consequently, Genode components that use the libc have to implement the Libc::Component::construct function but can also use the passed libc environment reference, which extends the Genode environment by safe access to the XML configuration data and a single VFS instance.
The application context enables the libc to suspend and resume the execution of the application at any appropriate time, e.g., when waiting in select for a file descriptor to become readable. The entrypoint context itself stays runnable on its own context and handles incoming signals - most importantly the signal that unblocks the suspended application code. This suspend-resume functionality works cooperatively and is hidden in the libc.
When using libc functions in the component, the code must indicate this intention by wrapping code into Libc::with_libc defined as a function taking a lambda-function argument in libc/component.h. This ensures that code from the libc is executed exclusively by the application context and, therefore, is suspendable. In fact, this is the way the posix library implements Libc::Component::construct:
void Libc::Component::construct(Libc::Env &env)
{
Libc::with_libc([&] () {
...
exit(main(argc, argv, envp));
});
}
Based on the with_libc feature, it is now possible to implement full-fledged Genode components with RPCs and signal handlers that also use the libc or C-based libraries. Our libc port also provides a component-compatible variant of select defined in libc/select.h.
|
Pure POSIX applications are not very special regarding their execution model. The only precaution that must be taken in an application is that it has to be linked to the posix library in the target.mk file.
LIBS = posix
This library implements Libc::Component::construct, prepares the environment and argument vector, and calls the ordinary main function of the application. So, POSIX applications never return from construct into the entrypoint and stay on the application context until the program exits.
Known limitations
In the current version, global constructors are executed by Genode's startup code before entering the application code by calling Component::construct. Since the libc is initialized not before its Component::construct function is executed, global constructors are called prior the libc initialization. Therefore, global constructors must not have any dependencies on blocking libc functions or any side effects that require a properly initialized libc. In the future, we plan to overcome this limitation by omitting the unconditional execution of global constructors at Genode's component-startup code, and instead leaving this step to the component-specific implementation of Component::construct. The libc's Component::construct function would then be able to execute the application's global constructors in the application's context.
Dynamically reconfigurable init component
The init component plays a central role for every Genode system. It starts the initial system components and interconnects them according to its configured policy. In complex system scenarios, it is also routinely used in a nested fashion as a subsystem-composition tool. For example, most subsystems started via the dynamic CLI-monitor runtime are actually init instances that, in turn, create a whole subsystem consisting of several components. With the current release, we strengthen the use of init as a generic system-composition tool, especially for dynamic scenarios.
Dynamic re-configuration
Until now, init used to respond to configuration changes by merely destroying all child components of the old configuration followed by the creation of all components of a new configuration from scratch. The new version enables init to apply configuration changes to a running scenario in a differential way. Children are restarted if any of their session routes change, new children can be added to a running scenario, or children can deliberately be removed. Furthermore, the new version is able to propagate configuration changes (modifications of <config> nodes) to its children without restarting them.
With these changes, init becomes a suitable basis for dynamic runtime environments that previously required custom child-management implementations (like CLI monitor, or launchpad).
State reporting
In anticipation of init's use as a dynamic runtime environment, we equipped init with the ability to report its internal state in the form of a "state" report. This feature can be enabled by placing a <report> node into init's configuration. The report node accepts the following arguments (with their default values shown):
- delay_ms="100"
-
specifies the number of milliseconds to wait before producing a new report. This way, many consecutive state changes - like they occur during startup - do not result in an overly large number of reports but are merged into one final report.
- buffer="4K"
-
the maximum size of the report in bytes. The attribute accepts the use of K/M/G as units.
- init_ram="no"
-
if enabled, the report will contain a <ram> node with the memory statistics of init.
- ids="no"
-
supplement the children in the report with unique IDs, which may be used to infer the lifetime of children across configuration updates in the future.
- requested="no"
-
if enabled, the report will contain information about all session requests initiated by the children.
- provided="no"
-
if enabled, the report will contain information about all sessions provided by all servers.
- session_args="no"
-
level of detail of the session information generated via requested or provided.
- child_ram="no"
-
if enabled, the report will contain a <ram> node for each child based on the information obtained from the child's RAM session.
Session-label rewriting
Init routes session requests by taking the requested service type and the session label into account. The latter is used by the server as a key for selecting a policy at the server side. To simplify server-side policies, we enhanced init with the support for rewriting session labels in the target node of a matching session route. For example, a Noux instance may have the following session route for the "home" file system:
<route>
<service name="File_system" label="home">
<child name="rump_fs"/>
</service>
...
</route>
At the rump_fs file-system server, the label of the file-system session will appear as "noux -> home". This information may be evaluated by rump_fs's server-side policy. However, when renaming the noux instance, we'd need to update this server-side policy.
With the new mechanism, the client's identity can be hidden from the server. The label could instead represent the role of the client, or a name of a physical resource. For example, the Noux route could be changed to this:
<route>
<service name="File_system" label="home">
<child name="rump_fs" label="primary_user"/>
</service>
...
</route>
When rump_fs receives the session request, it is presented with the label "primary_user". The fact that the client is "noux" is not taken into account for the server-side policy selection.
The label rewriting mechanism supersedes the former (and deliberately undocumented) practice of using <if-args> for special handling of session labels.
Routing of environment sessions
The init component used to create the CPU/RAM/PD/ROM sessions (the child environment) for its children by issuing session requests to its parent, which is typically core. This policy had been hard-wired. The new version enables the routing of environment sessions according to init's routing policy. Thereby, it becomes possible to route the child's PD, CPU, and RAM environment sessions in arbitrary ways, which simplifies scenarios that intercept those sessions, e.g., the CPU sampler.
Note that the latter ability should be used with caution because init needs to interact with these sessions to create/destruct a child. Normally, the sessions are provided by the parent. So init is safe at all times. If they are routed to a child however, init will naturally become dependent on this particular child.
Because there is no hard-wired policy regarding the environment sessions anymore, routes to respective services must be explicitly declared in the init configuration. For this reason, existing configurations need to be adjusted to provide valid routes for CPU/RAM/PD/ROM sessions.
For routing environment sessions depending on session labels, the existing label, label_prefix, and label_suffix attributes of <service> nodes are not suitable. Whereas the arguments given to those attributes are scoped with the name of the corresponding child, environment sessions do not reside within this scope as they are initiated by init, not the child. The new unscoped_label attribute complements the existing attributes with an unscoped variant that allows the definition of routing rules for all session requests, including init's requests for a child's environment sessions. For example, to route the ROM-session request for a child's dynamic linker, the following route would match:
<route> ... <service name="ROM" unscoped_label="ld.lib.so"> ... </service> ... </route>
Configurable RAM preservation
Init has a so-called quota-saturation feature, which hands out all remaining slack quota to a child by specifying an overly high RAM quota for the child. Init retains only a small amount of quota for itself, which is used to cover indirect costs such as a few capabilities created on behalf of the children, or memory used for buffering configuration data. The amount used to be hard-wired. In practice, however, it depends on the scale of the scenario. Hence, the new version makes the preservation configurable as follows:
<config> ... <resource name="RAM" preserve="1M"/> ... </config>
If not specified, init has a reasonable default of 160K (on 32 bit) and 320K (on 64 bit).
Base framework
Transition to new framework API
We are happy to report that the transition to the new framework API that we introduced in version 16.05 is almost complete.
We enabled compile-time warnings that trigger whenever deprecated parts of the API are discovered. There are still a few places left. So when building the current version, please don't mind the occasional "deprecated" warnings. They will disappear along with the deprecated parts of the API within the next release cycle.
Improved accounting of session meta data
With the new version, we improved the accounting for the backing store of session-state meta data. Originally, the session state was allocated by a child-local heap partition fed from the child's RAM session. However, while this approach was somehow practical from a runtime's (parent's) point of view, the child component could not count on the quota in its own RAM session. I.e., if the Child::heap grew at the parent side, the child's RAM session would magically diminish. This caused two problems. First, it violates assumptions of components like init that carefully manage their RAM resources (and give most of them away to their children). Second, if a child transfers most of its RAM session quota to another RAM session (like init does), the child's RAM session may actually not allow the parent's heap to grow, which is a very difficult error condition to deal with.
In the new version, there is no Child::heap anymore. Instead, session states are allocated from the runtime's RAM session. In order to let children pay for these costs, the parent withdraws the local session costs from the session quota donated from the child when the child initiates a new session. Hence, in principle, all components on the route of a session request take a small bite from the session quota to pay for their local book keeping
Consequently, the session quota that ends up at the server may become depleted more or less, depending on the route. In the case where the remaining quota is insufficient for a server, the server responds with QUOTA_EXCEEDED. Since this behavior must generally be expected, we equipped the client-side Env::session implementation with the ability to re-issue session requests with successively growing quota donations.
For several of core's services (ROM, IO_MEM, IRQ), the default session quota has now increased by 2 KiB, which should suffice for session requests of up to 3 hops as is the common case for most run scripts. For longer routes the retry mechanism, as described above, comes into effect. For the time being, we give a warning whenever the server-side quota check triggers this retry mechanism. The warning may potentially be removed at a later stage.
OS-level infrastructure and device drivers
New CHARACTER class of input events
Within a Genode system, user-input events are propagated via the input-session interface, which enables clients to receive batches of input events from an input server such as an input-device driver. There exist various types of events like relative or absolute motion events (for pointer devices), press or release events (for physical buttons or keys on a keyboard), or touch events. The event types used to be device-level events. In particular, press and release events for a keyboard refer to physical scancodes of the keys, not their symbolic meanings. The application of language-specific keyboard layouts or key repeat is left to the client. E.g., Genode's custom terminal implementation has built-in keyboard layouts or Genode's version of Qt5 used to rely on the keyboard layout as implemented by Qt's evdev back end.
With a growing number of textual applications, this client-side handling of keyboard layouts has become impractical and too inflexible. For example, a user may want to change the keyboard layout globally at runtime or a user may wish to connect multiple keyboards with different layouts to the same machine. Applications should not need to deal with these requirements. On the other hand, low-level device drivers should not be bothered with application-level problems like the interpretation of modifier key states. One may suppose that text-processing applications may simply use another higher-level interface (such as the terminal-session interface, which already has the notion of characters). However, we found that most GUI applications require both low-level events as well as the notion of characters.
Following these observations, we decided to supplement the existing input event types with a new CHARACTER type. In contrast to a low-level press or release event, a character event refers to the symbolic meaning of a pressed key. An input-event stream may contain both low-level and symbolic events. It is up to the application to interpret either of them - or both. Character events are not meant to be generated by an input driver directly. Instead, a dedicated (bump-in-the-wire) component is meant to parse a stream of low-level events and supplement it with high-level character events. The new input filter presented in Section Input-event filter is meant to play this role.
Character events are created via a dedicated Event constructor that takes an Event:Utf8 object as argument. Internally, the character is kept in the _code member. The Utf8 value can by retrieved by a recipient via the new utf8 method.
Terminal support
We added the handling of CHARACTER events to Genode's custom terminal component located at gems/src/server/terminal/. To avoid interpreting press/release events twice (at the input filter and by the terminal's built-in scancode tracker), the terminal's scancode tracker can be explicitly disabled via <config> <keyboard layout="none"/> </config>. In the future, the terminal's built-in scancode tracker will be removed. The use of the terminal with the input filter is illustrated by the terminal_echo.run script.
Keyboard-layout support for Qt5
We adjusted the input-event back end of Genode's Qt5 version to handle CHARACTER events. In fact, the back end handles both low-level press/release events and character events now. However, instead of subjecting the low-level events to Qt's built-in keyboard-layout handling (that would produce characters according to a hard-wired keyboard layout), we deliberately pass an invalid character to Qt whenever a low-level press/release event is observed. This way, the actual press/release events are ignored for symbolic keys but still handled for keys where the physical location is important (e.g., cursor keys). The second part of the puzzle is to pass Genode's character events as UTF-8 strings to Qt while leaving the low-level scan code undefined. Hence, Qt consumes Genode's character events directly without the attempt to apply a keyboard layout.
We changed our run-script templates for Qt5 applications to use this new mechanism such that all existing applications make use of the new facility. To select a different keyboard layout than the default en_us one, simply override the language_chargen function in your run script (after including qt5_common.inc) where "de" refers to the character map file os/src/server/input_filter/de.chargen:
proc language_chargen { } { return "de" }
Input-event filter
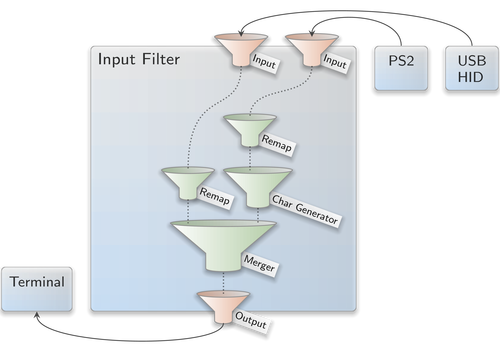
The new input-filter component is the successor of the existing input merger. In addition to merging input streams, the component applies several forms of input transformations, in particular the application of keyboard layouts to supplement the input-event stream with character events.
|
Configuration
An input-filter configuration consists of two parts: a declaration of input sources ("Input" connections) that the component should request and the definition of a filter chain. Each input source is defined via an <input> node with the name of the input source as name attribute and the session label as label attribute. The latter can be used to route several input sources to different components, i.e., input device drivers.
The filter chain is defined via one <output> node. It contains exactly one of the following filters:
- <input name="..."/>
-
Refers to the input source with the matching name.
- <remap>
-
Applies low-level key remapping to the events produced by another filter that is embedded as a child node.
It may contain any number of <key> nodes. Each of those key nodes must supply a name attribute and may feature an optional to attribute with the name of the key that should be reported instead of name and an optional sticky attribute. If the latter is set to "yes", the key behaves like a sticky key. That means, only press events are evaluated and every second press event is reported as a release event. This is useful for special keys like capslock.
- <merge>
-
Merges the results of any number of filters that appear as child nodes.
- <chargen>
-
Supplements the input-event stream of another filter with artificial CHARACTER events by applying character mapping rules. The originating filter is defined as a child node.
Character generator rules
Character-generator (<chargen>) rules are defined via the following sub nodes:
- <mod1>/<mod2>/<mod3>/<mod4>
-
Defines which physical keys are interpreted as modifier keys. Usually, <mod1> corresponds to shift, <mod2> to control, and <mod3> to altgr (on German keyboards). Each modifier node may host any number of <key> nodes with their corresponding name attributes. For example:
<mod1> <key name="KEY_LEFTSHIFT"/> <key name="KEY_RIGHTSHIFT"/> </mod1>
- <map mod1="..." mod2="..." mod3="..." mod4="...">
-
A <map> node contains a list of keys that emit a specified character when pressed. Any number of <map> nodes can be present. For each map node, the attributes mod1 to mod4 denote a condition which is evaluated. Each mod attribute has three possible values. If the attribute is not present, the state of the modifier does not matter. If set to yes, the modifier must be active. If set to no, the modifier must not be active.
Each <map> may contain any number of <key> subnodes. Each <key> must have the key name as name attribute. The to-be-emitted character is defined by the following attributes: ascii, char, or b0/b1/b2/b3. The ascii attribute accepts an integer value between 0 and 127, the char attribute accepts a single ASCII character, the b0/b1/b2/b3 attributes define the individual bytes of an UTF-8 character.
- <repeat delay_ms="500" rate_ms="250">
-
The <repeat> node defines the character-repeat delay and rate that triggers the periodic emission of the last produced character while the corresponding key is held.
- <include rom="...">
-
The <include> node includes further content into the <chargen> node and thereby allows the easy reuse of common rules. The included ROM must have a <chargen> top-level node.
Additional features
The input filter is able to respond to configuration updates as well as updates of included ROM modules. However, a new configuration is applied only if the input sources are in their idle state - that is, no key is pressed. This ensures the consistency of the generated key events (for each press event there must be a corresponding release event), on which clients of the input filter may depend. However, this deferred reconfiguration can be overridden by setting the force attribute of the <config> node to yes. If forced, the new configuration is applied immediately.
Examples
An automated test that exercises various corner cases of the input filter can be found at os/run/input_filter.run. For a practical example of how to use the input filter with the terminal, please refer to the gems/run/terminal_echo.run script.
SD-card driver improvements
With the current release, we modernized and unified our existing set of SD-card drivers. The formerly driver-specific benchmark has become generic and is now located at os/src/test/sd_card_bench/.
Furthermore, we added a new driver for the FreeScale i.MX6 SoC.
Platforms
Update of Muen to v0.8
The Muen Separation Kernel port has been updated to the latest development version 0.8, which brings a slew of new features. Most prominently Muen now has support for subject lifecycle management. This implies that it is now possible to restart subjects, e.g., an entire base-hw/Genode subsystem. Furthermore, the upgrade enables shutdown or reboot of the physical system via configuration in the system policy.
Further details regarding Muen v0.8 can be found in the projects release notes https://groups.google.com/forum/#!topic/muen-dev/yWzUGLLZ3sw.
Removal of stale features
We removed the following features that remained unused for at least two years:
- L4Linux on Fiasco.OC
-
L4Linux is a paravirtualized version of the Linux kernel that runs on top of the Fiasco.OC kernel. It remained unused and therefore outdated for two years now while we did not observe any ongoing interest in it from the Genode community either. In scenarios that call for Linux or a POSIX environment as a Genode subsystem, we found other solutions more appealing (in terms of stability, flexibility, and maintenance effort), e.g., VirtualBox on x86, or virtualization / TrustZone on ARM, or Noux.
- Xvfb integration on base-linux
-
The hybrid xvfb component allowed for the integration of multiple X servers in a nitpicker GUI environment on top of GNU/Linux. We introduced it in 2009 as an experimental feature. But since we are not facilitating Linux as a primary base platform for Genode, the xvfb support remained unused.
- Fiasco.OC-specific features of CLI monitor
-
The command-line-based dynamic component runtime called CLI monitor used to come with a few Fiasco.OC-specific extensions that interacted with the kernel debugger. We dropped those extensions to ease the maintenance of CLI monitor.